


Hello! Last week, we reached 3,000 subscribers, that’s awesome, thank you all!
Recently, I was going through the distributed systems reliability glossary brought by Antithesis & Jepsen, and I found their approach on availability models particularly interesting. Let’s dive into that.

Introduction
Here are two database whitepapers:
Megastore, a Google storage system:

Dynamo, an Amazon key-value store:

Both of these whitepapers use the term highly available. Of course, as a reader, we may expect these two whitepapers to mean the same thing when discussing high availability. After all, an orange is an orange, an apple is an apple, and a highly available system should be a highly available system. Yet, that’s not the case, and each paper means something different.
Let’s first look at what availability means, then discuss why high availability is a vague concept, and finally explore the different availability models.
Availability
In The CAP Theorem, we already discussed availability as:
Every request receives a non-error response, even if it may not contain the most up-to-date data.
However, this definition missed a crucial dimension: response time. Technically, a system could be available even if it responds after an hour. While such a system technically provides a non-error response, it fails to deliver a usable experience, severely compromising its practical availability from a user perspective.
This is where The PACELC Theorem offers a more practical perspective on availability. PACELC highlights that:
In the presence of a partition, a system must choose between availability and consistency.
In the absence of partition, a system must choose between latency (the upper-bound limit during which a request should receive a non-error response) and consistency.
So latency becomes part of availability. And that makes sense, right? If a system is too slow, it’s effectively down for the user. Availability isn’t just about uptime; it's also about whether the system is responsive in a meaningful timeframe.
High Availability
The term high availability is vague. Does it mean 99.9% uptime? 99.999%?
ScyllaDB, in their technical glossary says it’s about maintaining levels of uptime that exceed normal SLAs. That’s fine, but it’s also easy to game.
Say we define an SLA at 50%, then run at 80%. Technically, we exceeded it. Yet, does that mean we’re offering a highly available database? Probably not.
The Antithesis reliability glossary defines high availability as a system that is available more often than a single node. I quite like that one. If we take the availability of our best node and our system does worse than that, it’s not really highly available. Simple and practical.
Still, it’s not perfect. Let’s say we have five nodes, each available 50% of the time. With a write quorum of two, our write availability might still reach ~80%. But we’d still be down one request out of five. Hard to sell that as high availability.
To bring more clarity to the conversation, Antithesis introduced a set of availability models.
Availability Models
An availability model is something to help us define when an operation should succeed.
What do we mean by operation? It’s simply a request made to the system. That could be a read, a write, a ping, whatever the system is supposed to handle. Instead of thinking in terms of the whole system being up or down, we look at whether a specific request can succeed, even when parts of the system are failing.
Let’s explore three availability models.
Majority available
Definition: A system is majority available if when a majority of non-faulty nodes can communicate with one another, these nodes can execute some operations.
Consider a database composed of five nodes:
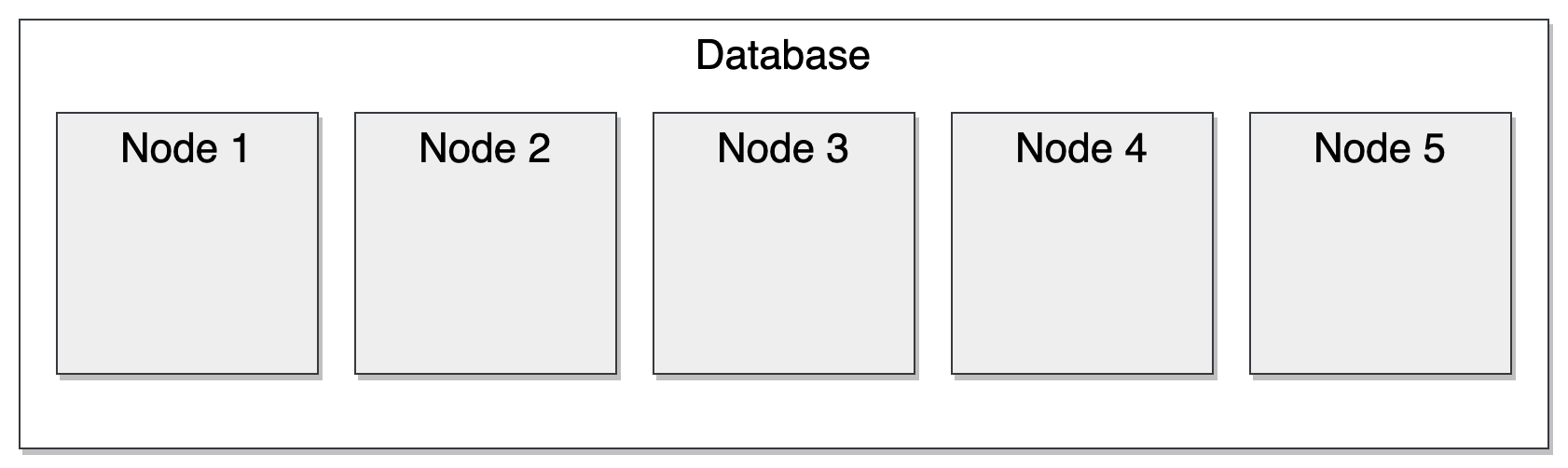
In the nominal case, everything works: a client connects, and the database can process all operations.
Now, imagine two nodes go down. Maybe they crash, maybe there’s a network issue causing a partition:
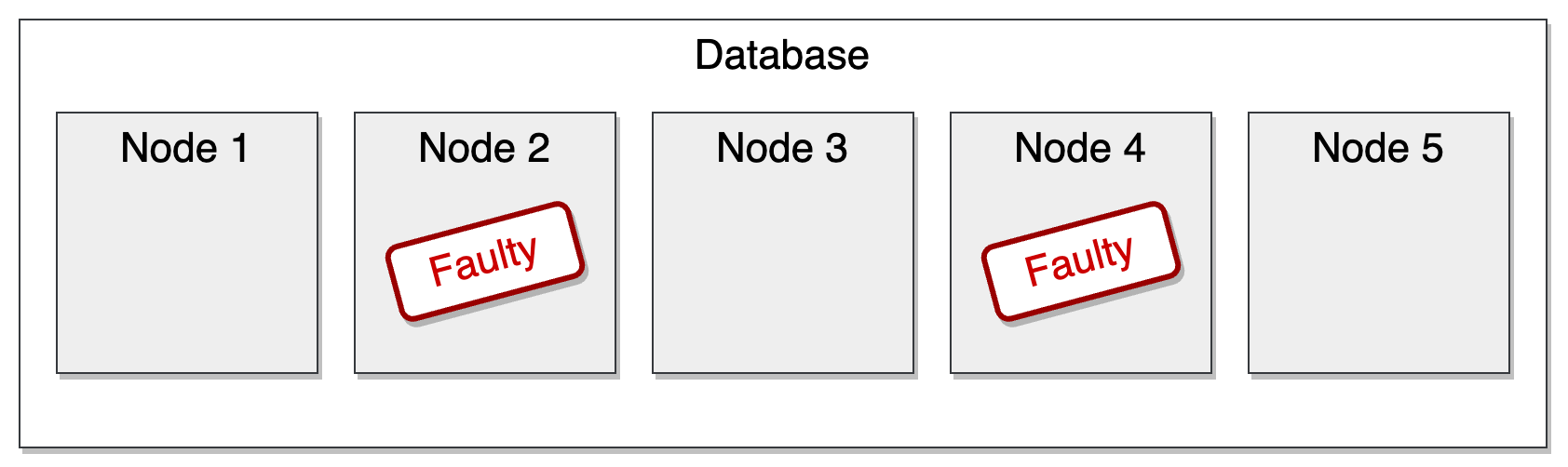
We’re left with three nodes that can still talk to each other. That’s a majority. If the database can still perform operations in this situation, we say it’s majority available.
That’s how the Megastore whitepaper defined highly available: being majority available.
This model is often used when consistency matters. For example, when a write or a leader election requires a majority to agree before responding to the client. So even if some nodes are unreachable, the system can still make safe progress as long as the majority is intact.
Total availability
Definition: A system is totally available if every non-faulty node can execute any operation.
Let’s take the same setup: a database with five nodes. This time, three of them are faulty:
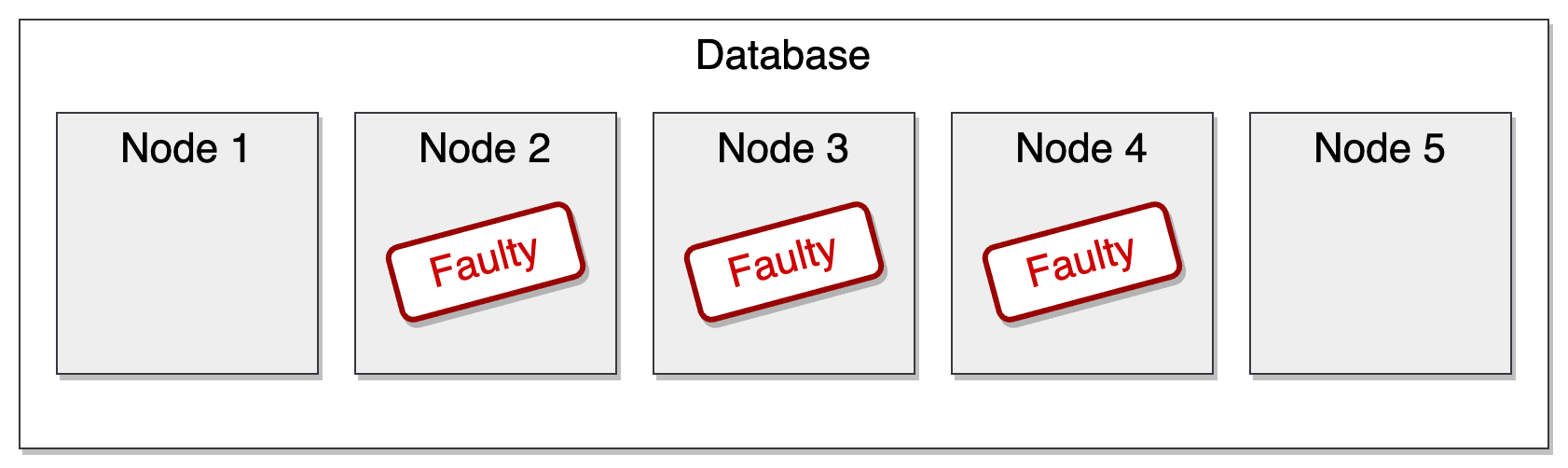
In a majority available model, we can’t do much as we don’t have a majority. But in a totally available model, the system can still handle operations.
Indeed, in this model, each non-faulty node can act on its own. It doesn’t need to coordinate with others or wait for a network round-trip. This model favors latency. Just handle the request and move on.
That’s how the Dynamo whitepaper defined highly available: being totally available.
The tradeoff is consistency. Totally available systems can’t enforce strong guarantees because the nodes don’t necessarily sync before responding. That’s why this model typically goes hand in hand with weaker consistency models.
Sticky Available
Definition: A system is sticky available if whenever a client’s transactions are executed against a copy of database state that reflects all of the client’s prior operations, it eventually receives a response, even in the presence of indefinitely long partitions.
Let’s look at an example. Two clients, A and B, are connected to a database and make updates over time:
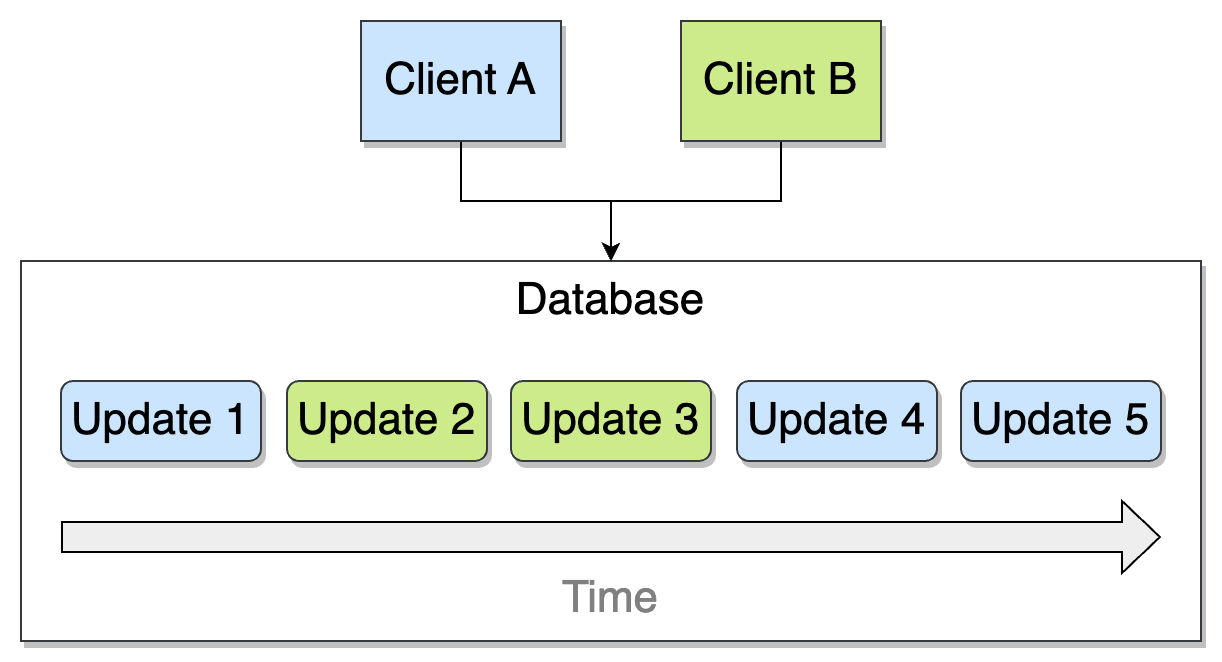
Sticky available means:
After update 5, client A will eventually get a response that reflects at least updates 1, 4, and 5.
After update 3, client B will eventually get a response that reflects at least updates 2 and 3.
How can we achieve that? It depends on how replication is handled by the system.
Fully Replicated System
In a fully replicated system, all nodes store the full dataset. Sticky availability can be achieved by making sure a client always talks to the same node.
Here’s the same example again, but now with client A always connected to node 1, and client B to node 2:
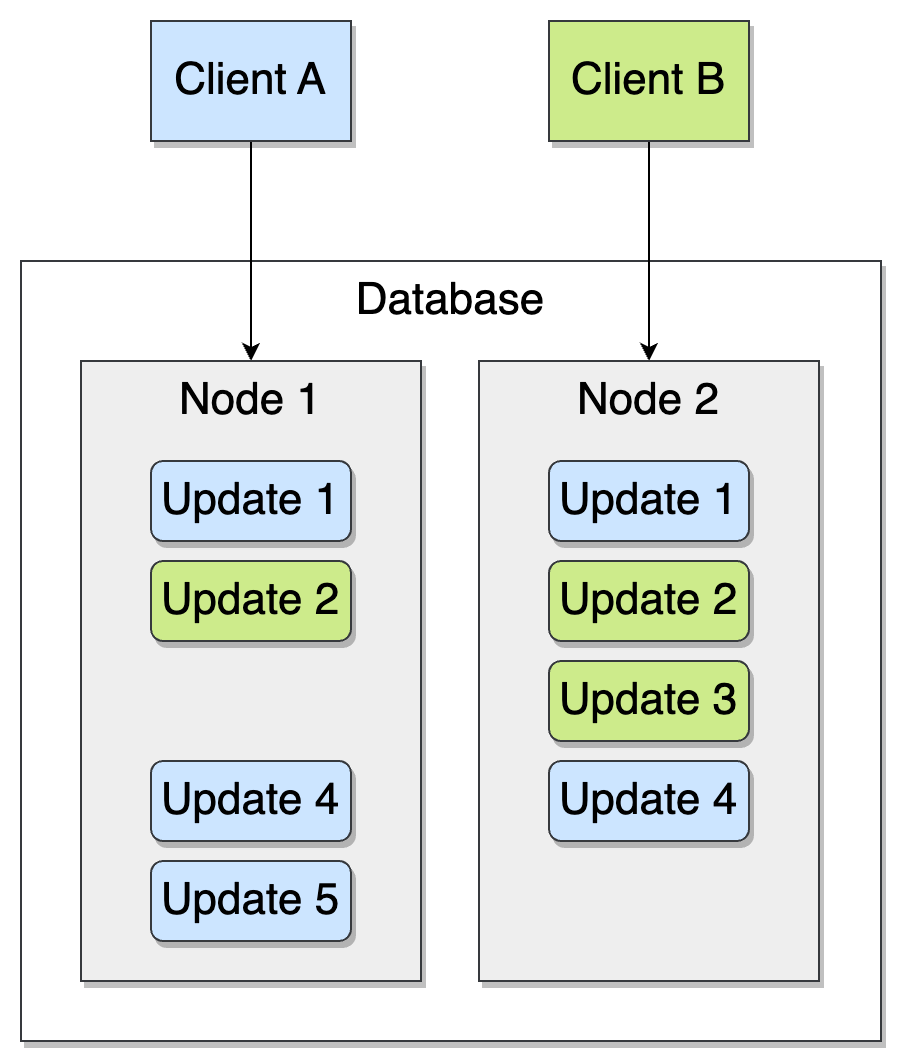
Here, node 2 hasn’t yet replicated update 5, and node 1 hasn’t yet replicated update 3. Still, since each client sticks to one node, they eventually see a consistent view of their own operations, despite possible failures such as a partition between the nodes.
Partially Replicated System
Now, let’s discuss a partially replicated system where nodes are replicas for subsets of data items.
Here’s a (dummy) partitioning system where even-numbered updates go to node 1 and odd-numbered ones to node 2:
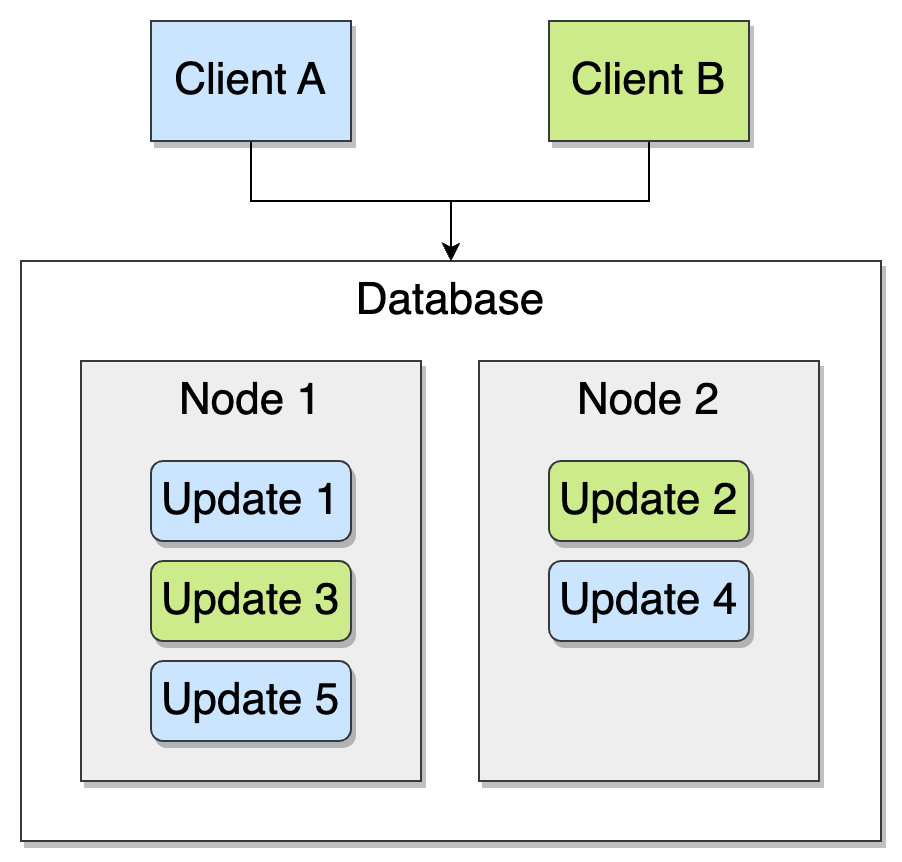
Here, clients can’t just stick to a single node. Instead, they must maintain stickiness with a single logical copy of the database, which may consist of multiple nodes.
Clients can also help implement this model by acting as servers themselves. For example, a client could cache its own reads and writes, allowing it to return responses even during indefinitely long partitions.
Summary
Highly available is too vague; watch out when you read or hear it. It might mean different things depending on the system or author.
Majority available means a majority of nodes can still perform some operations. This model supports stronger consistency.
Totally available means each non-faulty node can handle requests independently. It favors latency, but usually comes with weaker consistency.
Sticky available means clients can make progress as long as they keep talking to a replica that reflects their own history.
Availability models help us reason at the operation level, not just the system level. What matters is which operation can succeed, and under what conditions.

❤️ If you enjoyed the post, please consider giving it a like. It’s a helpful signal to decide what to write next.
💬 When someone says their system is “highly available,” what do you assume they mean?